Qualité d’annotation de données IA : le process simple pour réduire erreurs et biais
Publié le 03 Mar 2026 par Audrey Smith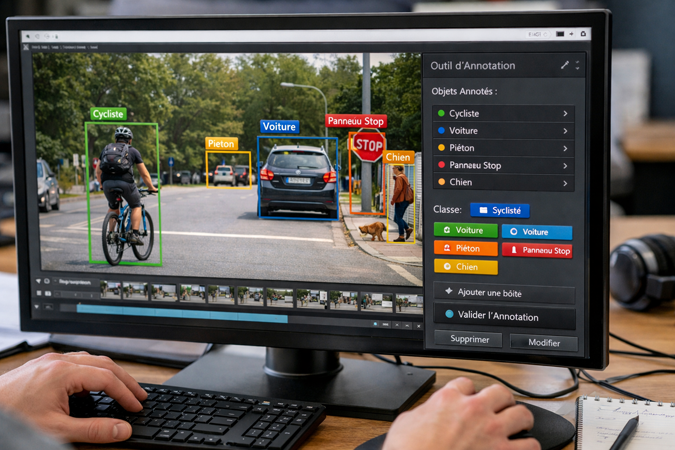
La qualité de l’annotation de données IA (data labeling) dépend moins des annotateurs que d’un cadre clair, d’un jeu de référence partagé et d’un contrôle qualité léger mais régulier. Il s’agit d’attribuer des labels (tags, classes, boîtes, spans, transcriptions) à des données textuelles, images, audio ou vidéo pour entraîner ou évaluer un modèle d’intelligence artificielle. Comme l’IA produit du prédictif via l’apprentissage automatique (et, selon les cas, des réseaux de neurones) à partir de données parfois hétérogènes, des labels ambigus conduisent le modèle à apprendre de mauvaises règles et alourdissent les itérations. Cet article propose donc un processus simple et reproductible pour réduire erreurs et biais. Il reste applicable avec des bases de données multiples, des données clients et un flux de données continu, surtout lorsque les sources et la qualité varient.
Points essentiels à retenir
- La qualité du data labeling repose surtout sur un cadre clair (taxonomie et règles), plus que sur le niveau des annotateurs.
- Avant de produire en volume, il faut une taxonomie nette, des guidelines courtes et un gold set partagé.
- En production, un QA léger mais régulier (sampling, double annotation ciblée, arbitrage) évite que les erreurs se propagent.
- Dans la durée, mesurer la cohérence et versionner les décisions permet de réduire erreurs et biais sans ralentir la cadence.
Table des matières
- Les types d’annotation et leurs pièges
- Définir la “qualité” d’un dataset annoté
- Les causes fréquentes d’erreurs en data labeling
- Process simple en 7 étapes pour réduire erreurs et biais
- 1) Concevoir la taxonomie (labels) avant d’ouvrir l’outil
- 2) Écrire des guidelines “opérationnelles” (1–2 pages)
- 3) Créer un “gold set” (jeu de référence)
- 4) Pilote de calibration (avant la production)
- 5) Production + QA léger (sampling)
- 6) Mesurer la cohérence (métriques simples)
- 7) Boucle d’amélioration (versioning + changelog)
- Réduire les biais dans un projet d’annotation
- Checklists prêtes à copier
- Outils et organisation
- Conclusion
- FAQ
Les types d’annotation et leurs pièges
Tous les projets d’annotation de données ne posent pas les mêmes problèmes. La qualité dépend souvent d’un point précis : définir ce qui compte (niveau de détail, frontières, exceptions) avant de lancer la production. Quand la production grossit, externaliser l’annotation à des annotateurs de données offshore peut sécuriser la cadence, avec des règles et un QA clairs.
- Classification : en catégorisation (ex. tickets support), les erreurs explosent lorsque les labels se chevauchent ou se ressemblent trop. Sans définitions nettes, deux annotateurs peuvent faire des choix “logiques” mais différents.
- Extraction / NER : en extraction d’entités, les frontières sont le piège principal. Où commence et où s’arrête une entité ? Sans conventions claires, la cohérence s’effondre vite, surtout sur des cas liés au traitement du langage et au langage humain (variantes, implicites, abréviations, noms composés).
- Segmentation / bounding boxes : côté image, l’arbitrage est permanent entre précision et temps. Sans standard de granularité, on obtient un dataset hétérogène, difficile à exploiter et à corriger.
- Transcription / speaker labeling : en audio, le bruit, les accents et le timing créent une variabilité invisible au départ mais coûteuse ensuite. Sans conventions (ponctuation, hésitations, chevauchements), la qualité devient instable.
Chaque type d’annotation impose une définition explicite de la granularité et des règles de décision, sinon les erreurs se propagent dès les premiers lots.
Définir la “qualité” d’un dataset annoté
Parler de qualité en annotation de données n’a de sens que si vous savez ce que vous évaluez. Pour éviter les débats subjectifs, appuyez-vous sur quatre dimensions simples et actionnables. D’abord, l’exactitude : attribuer le bon label, au bon endroit (classe, span, boîte, segmentation ou transcription).
Ensuite, la cohérence : prendre les mêmes décisions sur des cas similaires, entre annotateurs et dans le temps. Vient la couverture : disposer d’assez d’exemples par classe et de suffisamment de variété pour représenter le cas d’usage, y compris les situations difficiles.
Enfin, la traçabilité : pouvoir justifier et reproduire les décisions grâce à des guidelines versionnées et un historique des changements, afin de limiter les corrections coûteuses. Pour être opérationnel, reliez aussi la qualité à vos attributs clés (source, langue, canal, période, type de demande, niveau de bruit) afin de repérer rapidement où la cohérence chute.
Les causes fréquentes d’erreurs en data labeling
Quand les volumes de données augmentent, les écarts se multiplient si vous ne cadrez pas aussi ce qui se passe en amont (nettoyage, normalisation, mapping). Sans règles explicites pour transformer les données puis exploiter les données, vous introduisez du bruit “invisible” qui ressemble à un problème d’annotation, alors que la cause vient du pipeline.
- Une taxonomie mal conçue (trop de classes, labels trop proches, catégories qui se recoupent) crée de l’hésitation et fait chuter la cohérence.
- Des guidelines trop vagues laissent place à l’interprétation et augmentent le bruit dans le dataset.
- Des cas limites non documentés installent des confusions récurrentes.
- Des consignes qui changent sans versioning rendent la production instable et les corrections coûteuses.
- Vitesse, fatigue et routine favorisent les raccourcis et les erreurs.
- Des données déséquilibrées (classes rares, sources/langues/périodes sous-représentées) dégradent la qualité.
- Les biais de représentation apparaissent quand certains profils ou situations sont peu présents, et le modèle devient moins fiable sur ces cas.
Process simple en 7 étapes pour réduire erreurs et biais
L’objectif n’est pas de mettre en place un contrôle qualité lourd, mais un cadre simple, reproductible et facile à tenir dans le temps. Pour chaque étape, gardez la même logique : but, comment faire, livrable.
1) Concevoir la taxonomie (labels) avant d’ouvrir l’outil
But : éviter les confusions et limiter les interprétations.
Comment faire : démarrez avec peu de labels, puis n’ajoutez que si c’est nécessaire. Pour chaque label, définissez ce qui entre dedans, ce qui n’entre pas dedans, et ce qu’il ne faut surtout pas confondre.
Livrable : un dictionnaire de labels (définition + exemples + “ne pas confondre avec”).
2) Écrire des guidelines “opérationnelles” (1–2 pages)
But : réduire la variabilité entre annotateurs.
Comment faire : privilégiez des règles simples de type si/alors, précisez le niveau de granularité attendu, et définissez quoi faire en cas de doute (ex. “unknown”, “other”, escalade).
Livrable : un guide versionné + une section cas limites.
3) Créer un “gold set” (jeu de référence)
But : calibrer l’équipe et tester les règles sur des exemples réels.
Comment faire : sélectionnez 30 à 100 items représentatifs, annotés par un lead/reviewer, avec une justification quand c’est nécessaire.
Livrable : un gold set + des notes de décision.
4) Pilote de calibration (avant la production)
But : détecter les zones floues avant de produire en volume.
Comment faire : faites annoter le même mini-lot à toute l’équipe, comparez les résultats, puis ajustez la taxonomie et les guidelines sur les points de confusion.
Livrable : guidelines mises à jour + liste des confusions courantes.
5) Production + QA léger (sampling)
But : repérer les erreurs tôt, sans tout relire.
Comment faire : double annotez 5 à 10% des données, arbitrez via un reviewer, et ciblez en priorité les labels à risque (ceux qui se confondent le plus).
Livrable : un rapport QA (erreurs, confusions, actions correctives).
6) Mesurer la cohérence (métriques simples)
But : suivre la stabilité dans le temps.
Comment faire : calculez un taux d’accord global, un accord par label, et surveillez les paires de confusion (A vs B) pour voir où ça dérape.
Livrable : un tableau de suivi hebdo/mensuel.
7) Boucle d’amélioration (versioning + changelog)
But : réduire erreurs et biais au fil de l’eau, sans casser la production.
Comment faire : chaque semaine, sélectionnez une dizaine de cas limites, tranchez, et ajoutez la décision au guide. Si la taxonomie évolue, documentez l’impact et prévoyez une migration si nécessaire.
Livrable : un changelog, une nouvelle version des guidelines, et l’impact attendu.
Réduire les biais dans un projet d’annotation
Même avec un process solide, un dataset peut rester biaisé si certaines situations sont sous-représentées ou mal cadrées. L’idée n’est pas d’éliminer toute subjectivité, mais de limiter les biais qui dégradent la fiabilité du modèle en production — notamment sur des cas prédictifs (là où la décision du modèle déclenche une action concrète).
- Biais d’échantillonnage : vérifiez la représentativité des données (sources, périodes, profils, langues). Un dataset construit sur un seul canal ou une seule période apprend des régularités “locales” qui ne tiennent plus dès que le contexte change.
- Classes rares : ne les laissez pas se noyer dans la masse. Sur-échantillonnez-les si besoin, et ajoutez des consignes spécifiques pour éviter les confusions.
- Cas difficiles : intégrez volontairement des exemples ambigus au lieu de les éviter. Ce type d’“adversarial sampling” aide à renforcer les règles et à préparer le modèle aux situations réelles.
- Biais d’annotateur : réduisez l’effet “habitude” en faisant tourner les annotateurs sur les lots, et en ajoutant une double lecture ciblée sur les zones critiques.
Checklists prêtes à copier
Pour garder un niveau de qualité stable, les checklists servent de garde-fous. Elles évitent d’oublier une étape clé avant de lancer la production, et elles cadrent un QA simple, régulier, sans alourdir l’équipe.
Checklist “Avant production”
- Taxonomie validée et compréhensible (labels non chevauchants, “other/unknown” défini si nécessaire)
- Dictionnaire de labels prêt (définition, inclusions/exclusions, “ne pas confondre avec”)
- Guidelines versionnées (1–2 pages) avec règles si/alors et niveau de granularité
- Section cas limites déjà amorcée
- Gold set créé (30–100 items) et accessible à toute l’équipe
- Session de calibration réalisée sur un mini-lot commun, avec ajustements actés
- Rôle de reviewer/arbitre défini, avec un canal clair pour remonter les doutes
Checklist QA
- Taux de sampling défini (ex. 5–10% en double annotation)
- Labels “à risque” identifiés
- Règles d’arbitrage clarifiées (qui tranche, délai, format de décision)
- Suivi de l’accord global et par label planifié (hebdo ou mensuel)
- Liste des paires de confusion surveillée (A vs B)
- Actions correctives prévues (mise à jour guidelines, rappel équipe, ajustement taxonomie)
- Décisions diffusées et consignées dans un changelog (version + date + impact attendu)
Outils et organisation
L’objectif n’est pas d’empiler des outils, mais de sécuriser le process avec une organisation simple. Les bons choix dépendent surtout du type d’annotation (texte, image, audio) et de votre niveau d’exigence en QA.
Côté outils d’annotation, l’essentiel est de pouvoir annoter efficacement, exporter facilement, et gérer des consignes claires. Des solutions comme Label Studio (polyvalent), Doccano (plutôt orienté texte) ou Prodigy (plus “workflow” pour équipes techniques) couvrent la plupart des besoins selon les formats et les volumes.
Pour la documentation, centralisez les guidelines, le dictionnaire de labels et les décisions dans un espace unique, type Notion ou Confluence. L’important n’est pas l’outil, mais la discipline : versionner, dater, et garder une section “cas limites” facile à retrouver.
Enfin, si vos projets s’appuient sur des données clients issues de plusieurs bases de données, prenez le temps de centraliser les données et de documenter les transformations en amont. Si vos lots contiennent des informations sensibles, pensez aussi à cadrer la collecte et protection des données personnelles avant de lancer l’annotation. Un flux de données mal maîtrisé (nouvelle source, changement de format, export partiel) peut dégrader l’annotation sans que l’équipe ne s’en rende compte.
Dans ce contexte, vos outils d’analyse et un peu de data-mining (contrôles par source, par attribut, par classe, par période) servent de garde-fous, surtout dans une logique relation-client où la stabilité du modèle compte autant que sa performance. Une courte exploration de données en amont (contrôles rapides sur sources, champs manquants, doublons, distributions) évite de lancer l’annotation sur des lots déjà biaisés ou bruités.
Conclusion
La qualité d’annotation de données IA se joue rarement sur un “effort” supplémentaire, mais sur un cadre plus clair. Le trio le plus efficace reste simple : taxonomie solide, gold set de référence, et QA léger mais régulier.
Pour démarrer sans complexifier, lancez un pilote, puis mettez en place une double annotation sur 5 à 10% des données avec arbitrage. Une fois les cas limites documentés et les consignes stabilisées, vous pouvez augmenter le volume ou élargir l’équipe sans faire exploser les erreurs… ni les biais.
FAQ
Comment gérer l’annotation quand les données contiennent des informations sensibles ?
Avant l’annotation, mettez en place une règle claire de minimisation : retirer ou masquer ce qui n’est pas nécessaire (anonymisation, floutage, redaction). Ajoutez ensuite des consignes spécifiques sur ce qui doit être ignoré, comment signaler un contenu sensible, et qui peut y accéder.
Quand faut-il arrêter la double annotation ?
Quand la cohérence se stabilise et que les confusions récurrentes disparaissent. Vous pouvez alors réduire la double annotation et basculer vers un contrôle ciblé sur les labels sensibles, ou sur les lots “à risque” (données bruitées, nouvelles sources, nouveaux marchés).
Comment adapter le process si vous utilisez une annotation assistée par IA ?
L’assistance accélère, mais ne remplace pas le cadre. Gardez les mêmes bases (taxonomie, guidelines, gold set), puis contrôlez spécifiquement les erreurs “systématiques” de l’IA via un sampling dédié.
Quels signaux indiquent que la qualité se dégrade en production ?
Les signaux les plus fiables sont opérationnels : hausse des confusions entre deux labels, augmentation des arbitrages, multiplication des cas “Other/Unknown”, et retours récurrents des annotateurs sur des règles difficiles à appliquer.






